 Adam Dunkels, PhD
Adam Dunkels, PhD 
We discovered a weird bug deep inside our IoT platform that took us by surprise. The root cause turned out to be that the rand() function called the malloc() function.
Now we want to spread the word, so that everyone knows: rand() may – under certain conditions – call malloc(). What does
this mean to the average person? To most people, not much. In fact, not even
most software developers will be affected by this. But it did affect us.
What we are talking about here is very low-level. Very bare-metal. Way more bare-metal than most software developers will ever be. So let’s dive into it.

The Thingsquare IoT platform runs on devices that have ridiculously small amounts of memory.
Memory allocation is a challenge
The Thingsquare IoT platform runs on devices that have small amounts of memory. Very small. Sometimes as small as 10 kilobytes. And sometimes we can splurge with as much as 32 kilobytes. For most modern purposes, this is ridiculously small.
We therefore have to be very clever in how we manage this memory. In the Thingsquare system, we have three different types of memory allocation mechanisms:
- memb: the memory block allocator. Fixed-size blocks from static pools of blocks.
- mmem: the managed memory allocator. Dynamic-sized blocks, that may be rearranged to avoid fragmentation, from a static chunk of memory.
- bmem: the block memory heap allocator. Dynamic-sized blocks from a static chunk of memory.
And, because the system is written in the C programming language, we also use stack memory.
All of the above are based on one principle: Always pre-allocate everything at compile-time. This means that we know, beforehand, how much memory is being used. If we use too much, we won’t even be able to compile the code. Much less run it. What we end up with is a memory structure that looks like this:
The stack starts at the top of the memory and grows downwards. But we have to be careful – more about this below. The stack is followed by a bunch of memb, mmem, and bmem blocks. As well as other data that the code uses.
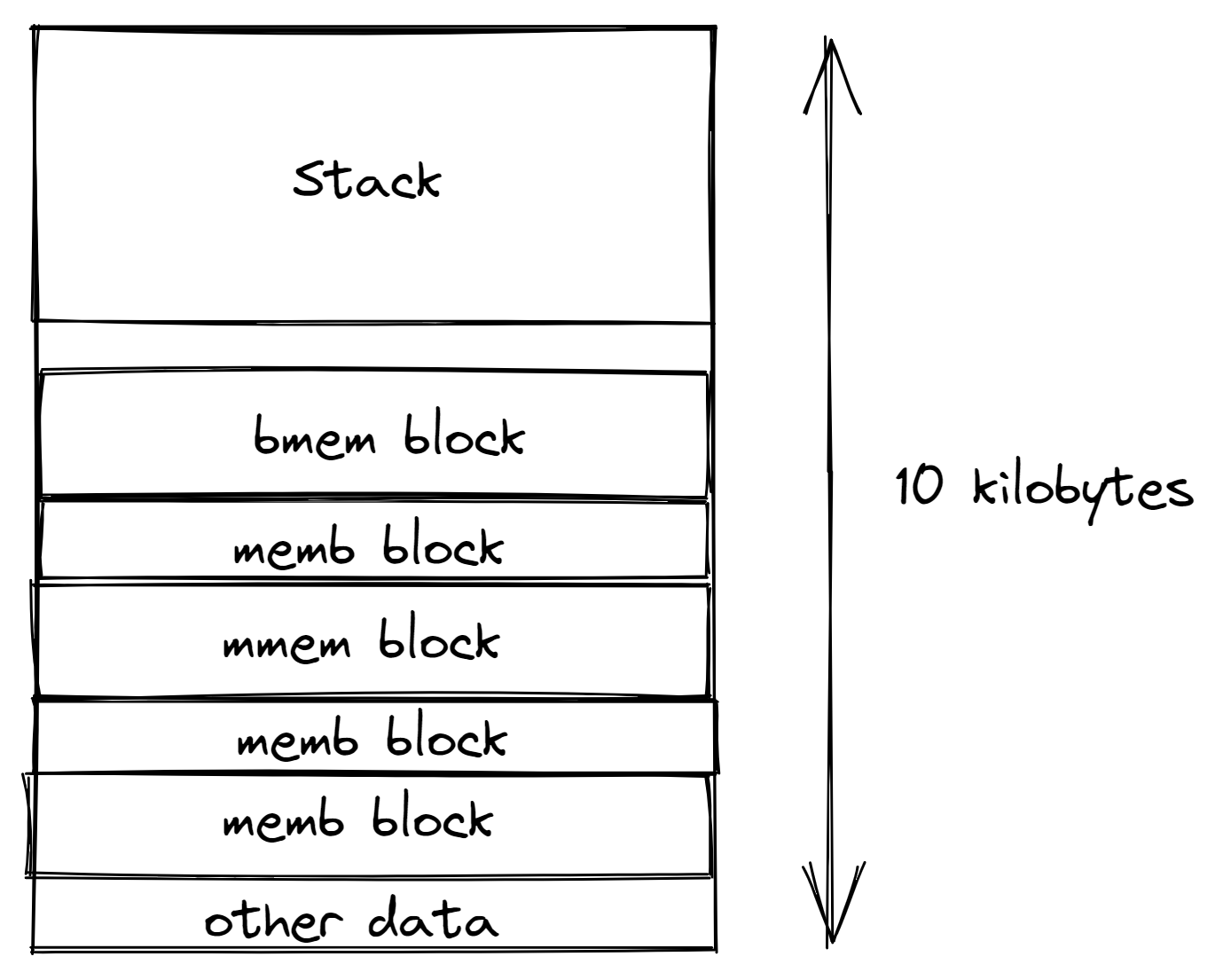
Because the memory is so tight, there is not much air in that memory layout. In most cases, it is almost 100% used.
malloc() might kill you
Note that there is one memory allocation mechanism that is not in the list above: the C language standard malloc()/free() mechanism.
Why?
Because with malloc()/free(), we don’t know beforehand how much memory that will be used.
We may end up with using more than we would expect, at runtime. And then, it might be too late. The device might already be dead.
Our devices are deployed in difficult-to-reach places. They need to be always available. We can’t afford them to run out of memory when we least expect it.
In fact, we go to great lengths to avoid any surprises.
We have a thorough test setup, which we run on every code change. This involves running the system in a set of network simulators, so that we can know for sure that the system works as expected. And during manufacturing, we do production testing to make sure that the hardware works.
So we can’t use malloc()/free(). And we don’t.
The stack doesn’t play nice
In the memory layout, the stack is a large chunk. How do we know how much to allocate to the stack?
The stack memory is somewhat tricky to allocate, because its maximum size is determined at runtime.
There is no silver bullet: we can’t predict it. So we need to measure it.
The way we do it is straightforward: at boot, we fill the stack memory with a known byte pattern. We then run the system. The system will use the stack. This will overwrite that byte pattern.
After we have run the system for some time, we check how much of that byte pattern is left. That gives us an idea of how much stack the system uses.
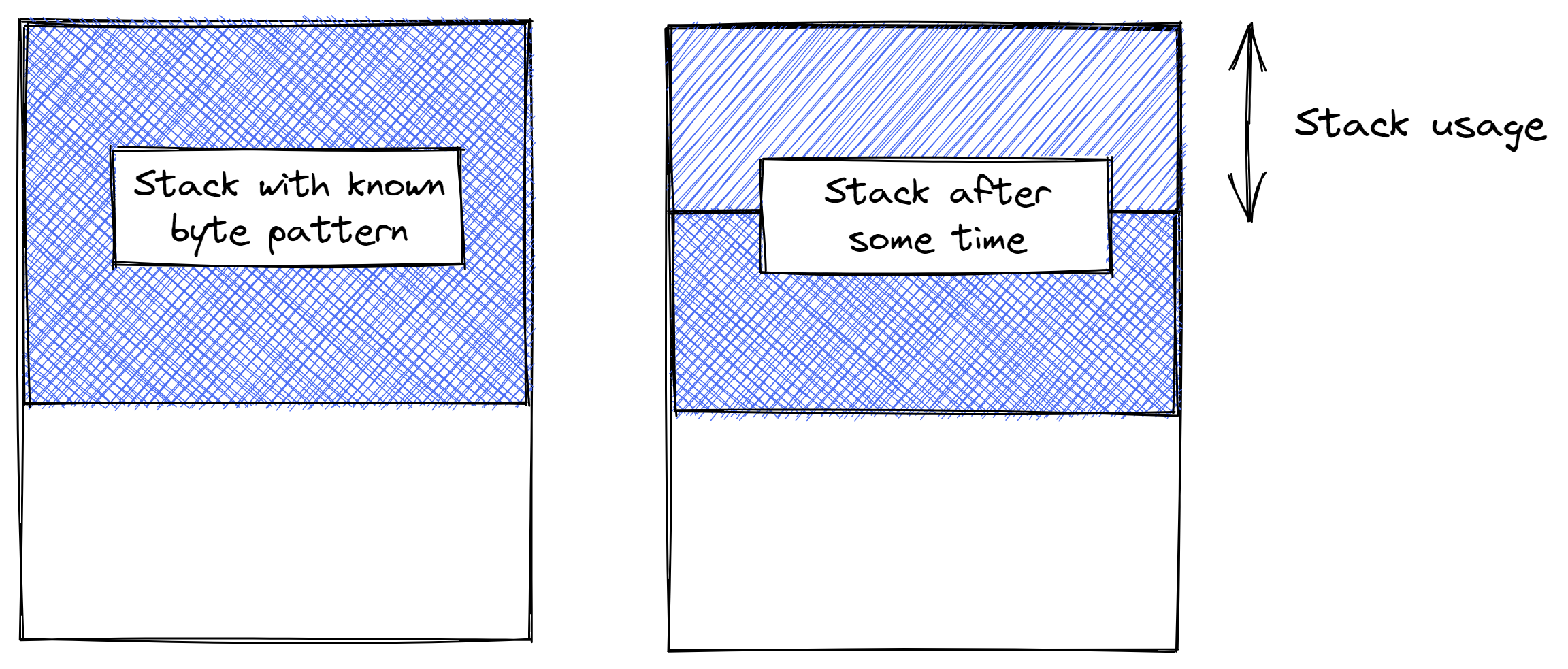
We then allocate a little more stack memory than what we think we need. To be on the safe side.
But we have one trick left: we can keep measuring that byte pattern, even when devices are deployed.
That bug
So all that leads up to that surprising bug that we stumbled across.
We found that some devices, in the field, were using more stack than we had assumed. And that was strange. Because we had made really sure that the stack size was good.
This made the device behave strangely. Unpredictably.
So what was going on?
We took a deeper look at one of the devices, in the lab. We added more places in the code where we measured the stack usage. To try to hone in on the part of the code that caused the overflow. And we found it:
rand();
Huh?
Yes, the standard C library function that produces pseudo-random numbers. This caused the stack to overflow. We use rand() in a few places in the code, where we need a quick pseudo-random number that doesn’t have to be cryptographically safe. It is a simple function that should not use much stack. So why was it overflowing the stack?
The culprit: rand()
The Thingsquare system use the newlib standard C library. This is open source, so we can look at the code.
This is the code of the rand() function, which looks familiar:
int
rand_r (unsigned int *seed)
{
long k;
long s = (long)(*seed);
if (s == 0)
s = 0x12345987;
k = s / 127773;
s = 16807 * (s - k * 127773) - 2836 * k;
if (s < 0)
s += 2147483647;
(*seed) = (unsigned int)s;
return (int)(s & RAND_MAX);
}
Why would this code use so much stack that it blew through its bounds?
There is no large arrays or structs allocated on the stack.
There is no recursion.
But wait! That’s rand_r(), not rand(). We’re looking at the wrong code. Because we were looking for something that looked familiar.
So the problem is not in this code. Let’s dig deeper.
The newlib library has a reentrancy layer that makes it possible to call functions multiple times, simultaneously.
And this reentrancy code is implemented with C macros. It is difficult to understand from a first glance. This is how the actual rand() function looks:
int
rand (void)
{
struct _reent *reent = _REENT;
/* This multiplier was obtained from Knuth, D.E., "The Art of
Computer Programming," Vol 2, Seminumerical Algorithms, Third
Edition, Addison-Wesley, 1998, p. 106 (line 26) & p. 108 */
_REENT_CHECK_RAND48(reent);
_REENT_RAND_NEXT(reent) =
_REENT_RAND_NEXT(reent) * __extension__ 6364136223846793005LL + 1;
return (int)((_REENT_RAND_NEXT(reent) >> 32) & RAND_MAX);
}
Maybe these calls are the problem?
And, yes, as it turns out, they are.
Deep inside that _REENT_CHECK_RAND48() macro, we find:
/* Generic _REENT check macro. */
#define _REENT_CHECK(var, what, type, size, init) do { \
struct _reent *_r = (var); \
if (_r->what == NULL) { \
_r->what = (type)malloc(size); \
__reent_assert(_r->what); \
init; \
} \
} while (0)
Oooops – a malloc()! That one killer function that we wanted to avoid.
But is it really used?
Yes, looking at the compiled code, we see that malloc() being called:
0001ff80 <rand>:
1ff80: 4b16 ldr r3, [pc, #88] ; (1ffdc <rand+0x5c>)
1ff82: b510 push {r4, lr}
1ff84: 681c ldr r4, [r3, #0]
1ff86: 6ba3 ldr r3, [r4, #56] ; 0x38
1ff88: b9b3 cbnz r3, 1ffb8 <rand+0x38>
1ff8a: 2018 movs r0, #24
1ff8c: f7ff fee4 bl 1fd58 <malloc>
1ff90: 4602 mov r2, r0
1ff92: 63a0 str r0, [r4, #56] ; 0x38
1ff94: b920 cbnz r0, 1ffa0 <rand+0x20>
1ff96: 4b12 ldr r3, [pc, #72] ; (1ffe0 <rand+0x60>)
1ff98: 4812 ldr r0, [pc, #72] ; (1ffe4 <rand+0x64>)
1ff9a: 214e movs r1, #78 ; 0x4e
1ff9c: f000 f952 bl 20244 <__assert_func>
1ffa0: 4911 ldr r1, [pc, #68] ; (1ffe8 <rand+0x68>)
1ffa2: 4b12 ldr r3, [pc, #72] ; (1ffec <rand+0x6c>)
1ffa4: e9c0 1300 strd r1, r3, [r0]
1ffa8: 4b11 ldr r3, [pc, #68] ; (1fff0 <rand+0x70>)
1ffaa: 6083 str r3, [r0, #8]
1ffac: 230b movs r3, #11
1ffae: 8183 strh r3, [r0, #12]
1ffb0: 2100 movs r1, #0
1ffb2: 2001 movs r0, #1
1ffb4: e9c2 0104 strd r0, r1, [r2, #16]
1ffb8: 6ba4 ldr r4, [r4, #56] ; 0x38
1ffba: 4a0e ldr r2, [pc, #56] ; (1fff4 <rand+0x74>)
1ffbc: 6920 ldr r0, [r4, #16]
1ffbe: 6963 ldr r3, [r4, #20]
1ffc0: 490d ldr r1, [pc, #52] ; (1fff8 <rand+0x78>)
1ffc2: 4342 muls r2, r0
1ffc4: fb01 2203 mla r2, r1, r3, r2
1ffc8: fba0 0101 umull r0, r1, r0, r1
1ffcc: 1c43 adds r3, r0, #1
1ffce: eb42 0001 adc.w r0, r2, r1
1ffd2: e9c4 3004 strd r3, r0, [r4, #16]
1ffd6: f020 4000 bic.w r0, r0, #2147483648 ; 0x80000000
1ffda: bd10 pop {r4, pc}
1ffdc: 20000770 .word 0x20000770
1ffe0: 00027bfc .word 0x00027bfc
1ffe4: 00027c13 .word 0x00027c13
1ffe8: abcd330e .word 0xabcd330e
1ffec: e66d1234 .word 0xe66d1234
1fff0: 0005deec .word 0x0005deec
1fff4: 5851f42d .word 0x5851f42d
1fff8: 4c957f2d .word 0x4c957f2d
To achieve reentrancy, the newlib code uses malloc() to allocate state for its randomness, so that it can be called multiple times.
Just what we wanted to avoid.
But why does malloc() result in the stack being blown?
Because malloc(), in its default implementation, uses memory between the highest allocated byte, and the stack. In most cases, for large systems, this is fine. Because there is plenty of free memory between the highest allocated byte and the stack.
But not in our case.
We don’t have much free memory. So that call to malloc() will interfere with the stack, immediately.
And fortunately we were able to find this by keeping a check on the stack.
But why did this happen now? We have been running this code for years on end with no problems. As it turns out, the reason is that we recently upgraded the arm-gcc version. And this version has its newlib built with reentrancy support, which the previous versions did not have.
The solution?
Fortunately, the solution is simple: we just stop using rand().
Instead, we provide our own pseudo-random function. For example, the PCG random number generator. Also, we added another regression test that explicitcly checks for occurences of the malloc() code in generated binaries.
 How to run a city-wide wireless network from a drawer
How to run a city-wide wireless network from a drawer